Setting up a Provider
To use inksprite’s AI tools, you’ll need to connect to a provider. We have an out-of-the box integration with OpenRouter, which is the cheapest and best option for most users.
OpenRouter (Recommended)
Section titled “OpenRouter (Recommended)”OpenRouter is the easiest way to get started with inksprite’s AI tools. OpenRouter provides access to a huge range of providers and models at relatively low cost (or even free).
The other advantage of OpenRouter is that it acts as a proxy between you and a provider, which is useful if your story happens to toe the line when it comes to a provider’s terms of use.
Setting up a Key
Section titled “Setting up a Key”The Getting Started guide provides step-by-step instructions for connecting to OpenRouter.
You can also create an API key and add it manually from the Settings menu, under AI -> Write or Chat -> Model -> Provider.
OpenRouter is a “pay-as-you-go” service. You pay for each request you make to the AI. The cost is determined based on a few factors:
- Model: Larger and more powerful models tend to be more expensive
- Context Size: The size of the prompt you send to the AI
- Output Size: The amount of text the model generates
Cost is represented in dollars per million tokens. For example, the model below is priced at $0.25 per million input tokens and $0.88 per million output tokens.

As a point of reference, generating a short second chapter of the example story used throughout these docs cost slightly less than 2 cents. A 3 hour solo Dungeons and Dragons session using Claude Sonnet with a detailed Lorebook cost $1.94.
Free Models
Section titled “Free Models”A number of free models are available through OpenRouter. These models have rate limits, so you may occasionally see errors when using these models. Adding $10 of credits puts you in a higher “tier” with less restrictive limits, even for free models.
Other Providers
Section titled “Other Providers”inksprite should work with any OpenAI compatible endpoint. However, there are a lot of AI services out there, and we’ve only tested a few of them. If you have issues getting a service to work, let us know.
Local Models
Section titled “Local Models”Using inksprite with a locally hosted model is a great option if you’re concerned about privacy or want to use a custom fine-tuned model.
You will need fairly powerful hardware to run a model locally. A detailed guide on model hosting is out of scope here, but you’ll find plenty of resources online. Two good options are vLLM and LM Studio.
We’ll use LM Studio for the sake of this example.
Follow the LM Studio documentation to download and load a model from Hugging Face, then start the developer server. By default, the server is reachable at http://localhost/1234.

From the Settings menu, open the “Configure Provider” menu under AI -> Write or Chat -> Model -> Provider.
Create a new “Generic” Provider named “LM Studio”, and set the endpoint to http://localhost/1234/v1. You won’t need an API key in this case.
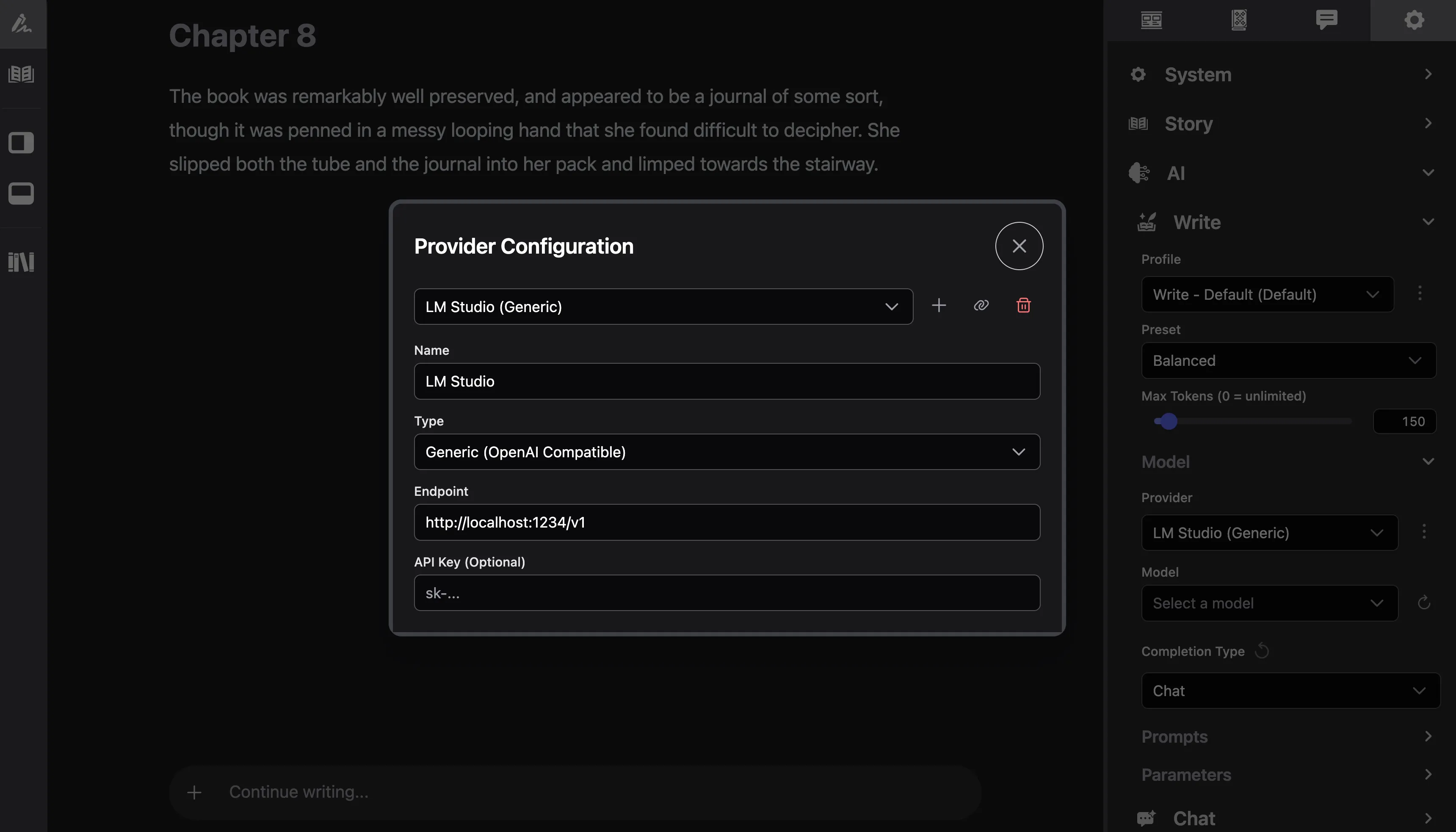
Use “Test Connection” to validate that everything is working. You may need to refresh the model list after closing the Provider menu.

Runpod
Section titled “Runpod”Runpod is a service that allows you to rent cloud GPUs at no commitment and relatively low cost.
If you want to host a large LLM, this is a considerably cheaper and easier option than building your own server. This is a good way to get access to models that have been fine-tuned for writing fiction or role play that aren’t hosted on OpenRouter.
Some examples of popular models you might want to try:
- https://huggingface.co/TheDrummer/Behemoth-X-123B-v2
- https://huggingface.co/sophosympatheia/Midnight-Miqu-70B-v1.5
- https://huggingface.co/mlabonne/gemma-3-27b-it-abliterated-GGUF
A guide to hosting an LLM on Runpod is out of scope here, but there are lots of resources online. Once you have your pod running, all you need is the API endpoint.